
斯普大数据仓库平台(SP-DW)不仅具有传统数据仓库的特性,同时融合了hadoop大数据处理能力,能够帮助企业轻松构建面向主题的、集成的、稳定的、不同时间、具有海量数据的企业数据中心。

一般的PC级服务器就可以非常廉价的搭建一个支持大规模数据量存储和应用的大数据分布式数据库,平滑迁移,原有应用可通过通用数据库接口连接,保持最大兼容性。

斯普大数据仓库(SP-DW)可实现TB级到PB级数据的高速存储和扩充;根据需求任意选择节点类型和数量构建企业数据存储集群,支持界面UI和API接口操作,可对集群进行停止、启动、增加、删除等相关操作,弹性释放资源,优化资源利用率。且SP-DW具有不间断运行能力,可以从失效的子服务开始部分重启运行,而不是重启整个任务,这对于企业应用来说至关重要。

独有的Hadoop+MPP超融合架构结合Hadoop批处理和MPP实时处理的优势,比Hive性能快10-100倍,同时满足结构化、半结构化和非结构化数据的处理要求,支持要求极高的事务型操作,并在不同的容错、一致性、负载要求下,保持一贯的高性能,完美支撑OLAP和轻量级的OLTP应用,对于重复查询可以达到秒级响应;对于开放式查询,也可以达到分钟级别的返回。

提供业内性能领先的兼容ANSI SQL国际标准的SQL-on-Hadoop查询引擎。SP-DW对SQL的全兼容,大大降低了大数据的使用门槛,让传统数据库用户在不改变操作开发习惯的前提下,无缝迁移到大数据架构之上进行数据分析,只用SQL语言就能随心所欲支配Hadoop。

企业采用Hadoop的主要用途不仅应用于大容量数据的提取和存储,越来越多的应用于实时商业分析和数据挖掘领域,这种快速扩张的需求直接推动了可同时提供批量处理和实时交互式分析混合架构的发展。SP-DW超融合架构通过与Kafka集成,结合SparkR实现流处理分析的秒极响应,轻松实现完整的Lamda数据分析架构,使得实时数据和历史数据得以全面激活和应用。
解决如何经济并高效的分析处理PB级海量数据的问题。
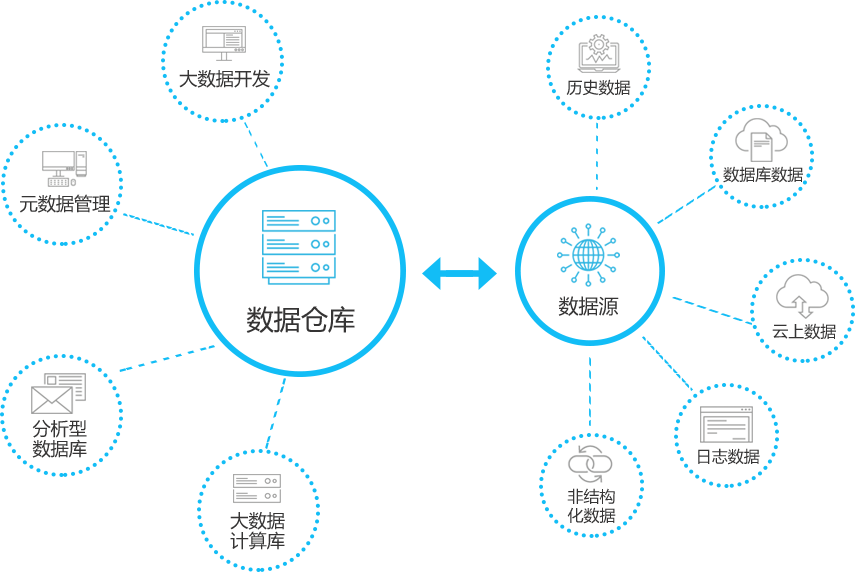
对数据生成链路进行监控,包括数据资产生命周期,数据字典,血缘关系等管理。
将业务数据进行存储后根据对应的数据仓库模型,对数据进行加工处理为分主题归类的数据。


大数据计算服务能够帮助用户做更深度、更复杂的加工,而不用担心计算效率问题。
对数据加工全过程进行跟踪,让数据工程师能随时掌控数据生产过程,保证数据的稳定产出。
支持海量PB级数据的存储,轻松应对大数据时代数据存储问题。